DALL·E 2 and Stable Diffusion Model Architectures: A high level overview
From what I learnt after hours of going through research papers

Came to web3 for the hype, stayed for the community.
Why was this necessary?
I was actually writing on the results I got while playing with DALL·E 2 and Stable Diffusion. I started that article by explaining some of the basic terms and a basic overview of their model architectures. Unfortunately it was becoming so long that I had to separate this into its own post.
Explaining the terms
Instead of going into the fine implementation-level details, I'll give a bird's-eye view of how some of the stuff works before diving into the real thing.
What's diffusion
It's a new kid on the block.
Till date, generative imaging was predominated by
- generative adversarial networks (GANs) and
- variational autoencoders (VAEs)
Diffusion is a new model architecture which creates images from noise, by learning how to repeatedly remove noise, guided by a prompt. And this method works like a charm, to say the least.
An image is taken, and some gaussian noise is added to it. The diffusion model is trained to remove this particular noise in a backward step. Repeating the noise addition step multiple times produces an image which looks like static. The diffusion model is built to convert this back into the original image, in multiple steps, guided by a prompt.
The definition of what this prompt exactly is, or its implementation varies model to model. A basic one is an embedding of the image caption.
DALL·E 2: Model architecture
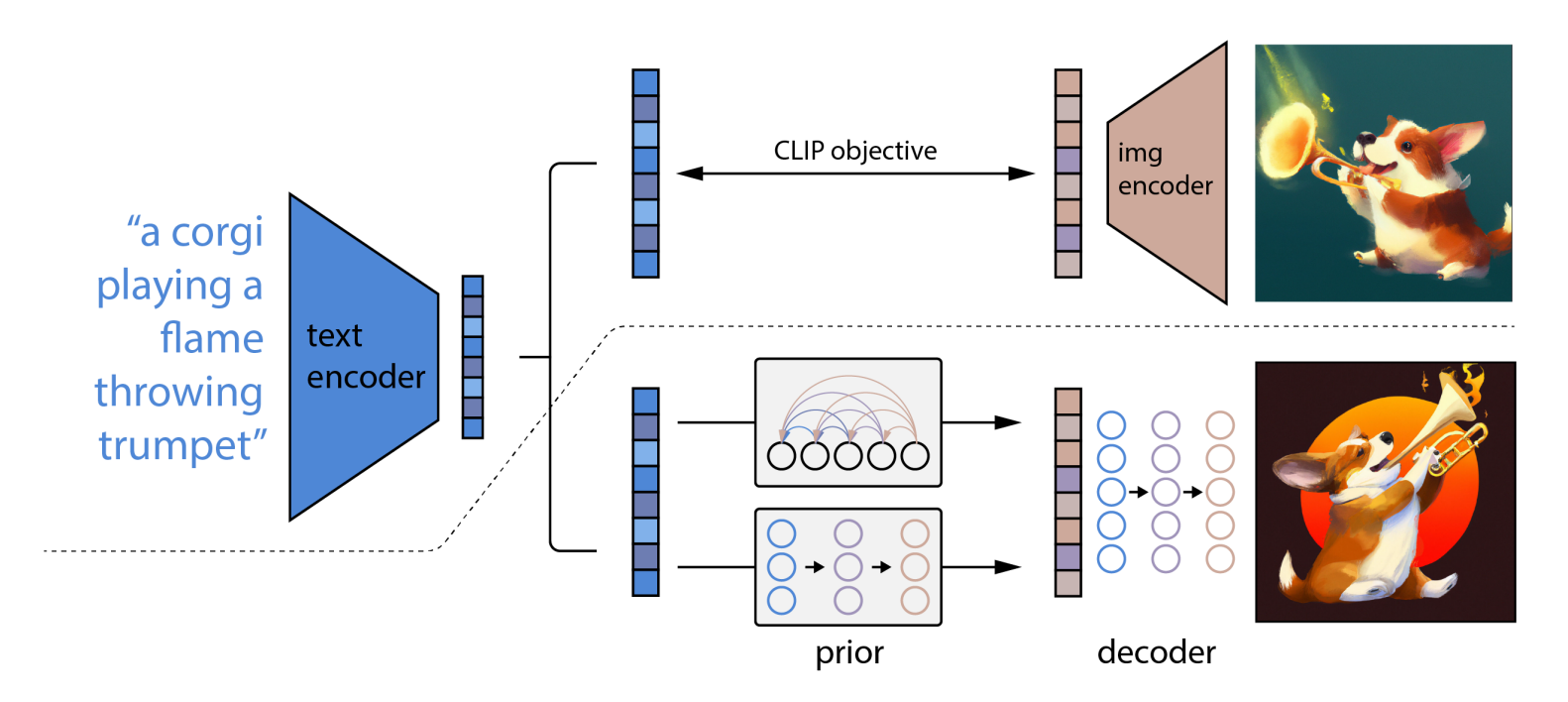
This is a screenshot from the DALL·E 2 paper, Hierarchical Text-Conditional Image Generation with CLIP Latents.
The model is fed a text prompt. The initial text encoder is a CLIP model which outputs an embedding which is "a joint representation space for text and images". That means CLIP would represent a photo of a stream flowing through the woods in the same way as it would represent the text "a photo of a stream flowing through the woods".
Thus CLIP's representation converges the semantics and visuals of a particular description.
DALL·E trains 2 models: the prior and the decoder. The CLIP model is frozen during training.
The prior network converts the text embedding into an image embedding. A static image is conditioned using this image embedding, to help guide the decoder as to what image to produce.
After conditioning, it is fed into the diffusion decoder network. This repeatedly denoises the conditioned image representation to produce the final image.
How's Stable Diffusion different?
Diffusion models like DALL·E and Imagen have an extremely high cost of computation. This is partly solved by stable diffusion by something called a latent space.
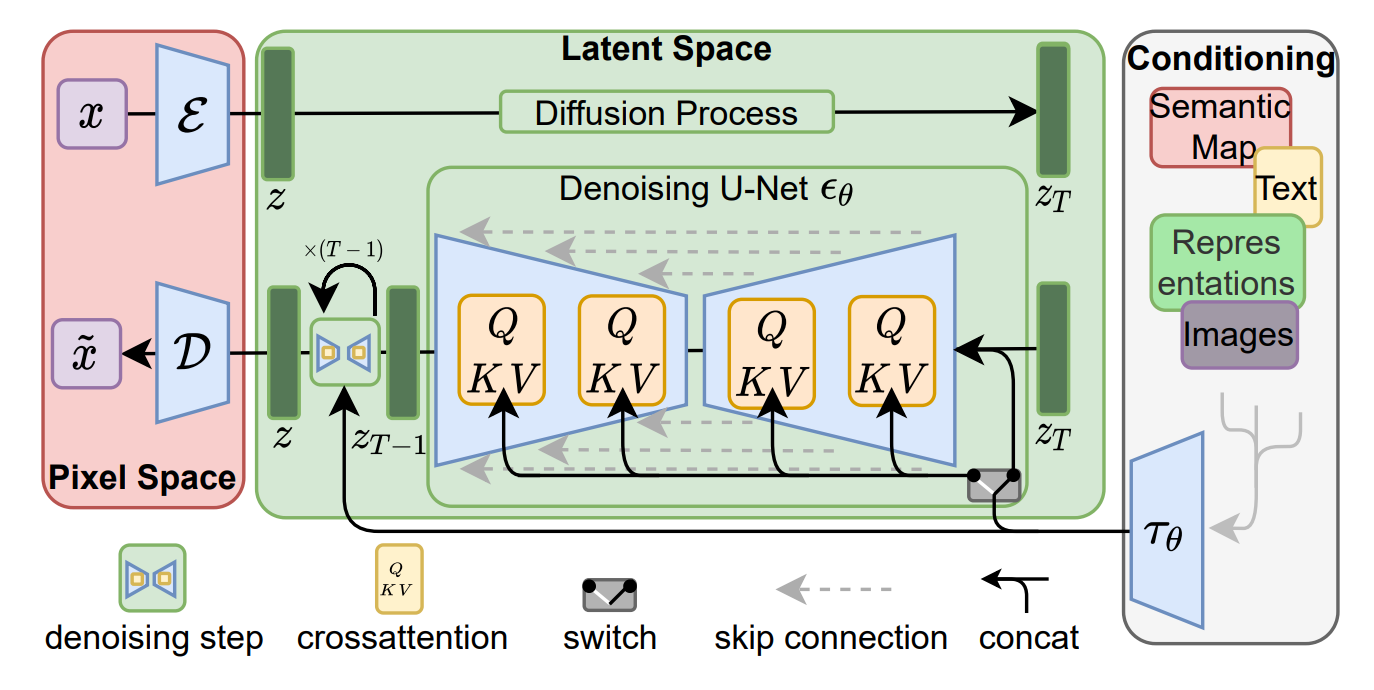
This image, taken directly from High-Resolution Image Synthesis with Latent Diffusion Models, shows the model architecture for stable diffusion.
The initial encoder converts the input into the highly compressed and information dense representation in the latent space (the green zone). Using this compressed versions is highly efficient, computationally, because they have matrices of lesser sizes. Now this latent space representation is diffused to produce the image that needs to be given to the decoder network.
Before that is the conditioning step. One interesting thing to notice is that the conditioning (text or image) is applied using an attention mechanism. So that brings a transformer component to this model. This conditioned representation is then fed into the denoising U-Net.
The pre-final step converts this representation in the latent space back to the pixel space (image form). This output in the pixel space is decoded into the real-world output by the decoder in the last step (right below the encoder).
Now, onto the main thing
With that out of the way, we can focus on the actual images generated by these models. If you look at an image for some time, interesting patterns begin to surface. You begin to think like the model itself.
I'll post all about it in 3 days!




